mirror of
https://github.com/harvard-edge/cs249r_book.git
synced 2026-04-30 01:29:07 -05:00
329 lines
37 KiB
Plaintext
329 lines
37 KiB
Plaintext
# Deep Learning Primer
|
||
|
||
## Overview
|
||
|
||
### Definition and Importance
|
||
|
||
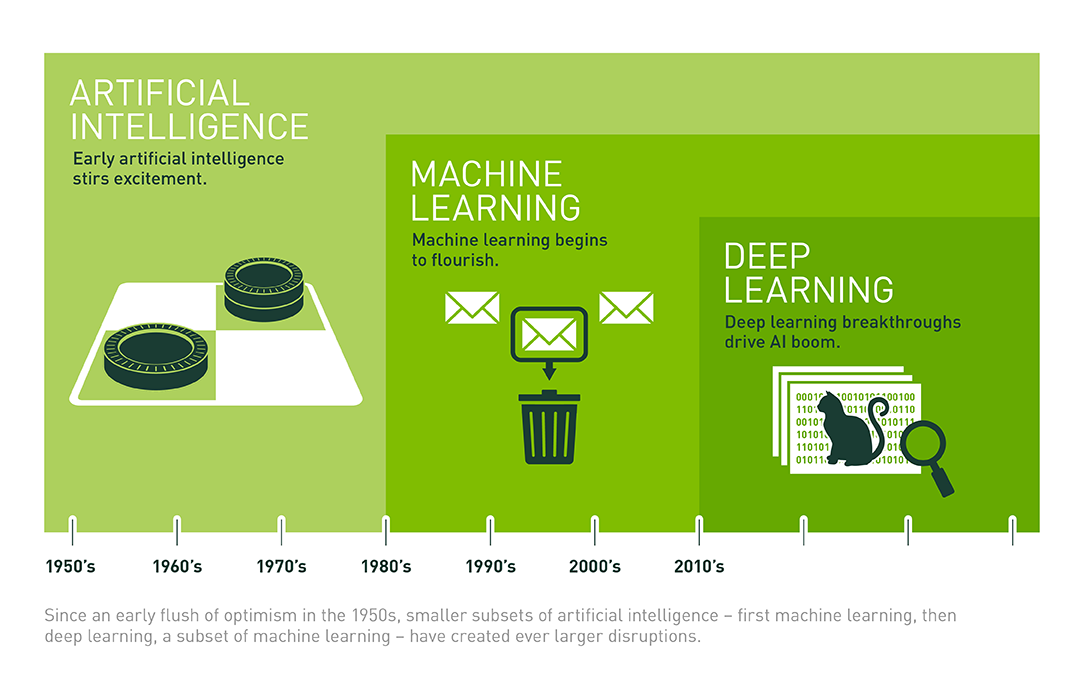
Deep learning, a subset of machine learning and artificial intelligence (AI), involves algorithms inspired by the structure and function of the human brain, called artificial neural networks. It stands as a cornerstone in the field of AI, spearheading advancements in various domains including computer vision, natural language processing, and autonomous vehicles. Its relevance in embedded AI systems is underscored by its ability to facilitate complex computations and predictions, leveraging the limited resources available in embedded environments.
|
||
|
||
|
||
|
||
### Brief History of Deep Learning
|
||
|
||
The concept of deep learning has its roots in the early artificial neural networks. It has witnessed several waves of popularity, starting with the introduction of the Perceptron in the 1950s [@rosenblatt1957perceptron], followed by the development of backpropagation algorithms in the 1980s [@rumelhart1986learning].
|
||
|
||
The term _deep learning_ emerged in the 2000s, marked by breakthroughs in computational power and data availability. Key milestones include the successful training of deep networks such as AlexNet [@krizhevsky2012imagenet] by [Geoffrey Hinton](https://amturing.acm.org/award_winners/hinton_4791679.cfm), one of the god fathers of AI, and the resurgence of neural networks as a potent tool for data analysis and modeling.
|
||
|
||
In recent years, deep learning has witnessed exponential growth, becoming a transformative force across various industries. @fig-trends shows that we are currently in the third era of deep learning. From 1952 to 2010, computational growth followed an 18-month doubling pattern. This dramatically accelerated to a 6-month cycle from 2010 to 2022. At the same time, we witnessed the advent of major-scale models between 2015 and 2022; these appeared 2 to 3 orders of magnitude faster and followed a 10-month doubling cycle.
|
||
|
||
{#fig-trends}
|
||
|
||
A confluence of factors has fueled this surge, including advancements in computational power, the proliferation of big data, and improvements in algorithmic designs. Firstly, the expansion of computational capabilities, particularly the advent of Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) [@jouppi2017datacenter], has significantly accelerated the training and inference times of deep learning models. These hardware advancements have made it feasible to construct and train more complex, deeper networks than were possible in the earlier years.
|
||
|
||
Secondly, the digital revolution has brought forth an abundance of "big" data, providing rich material for deep learning models to learn from and excel in tasks such as image and speech recognition, language translation, and game playing. The availability of large, labeled datasets has been instrumental in the refinement and successful deployment of deep learning applications in real-world scenarios.
|
||
|
||
Additionally, collaborations and open-source initiatives have fostered a vibrant community of researchers and practitioners, propelling rapid advancements in deep learning techniques. Innovations such as deep reinforcement learning, transfer learning, and generative adversarial networks have expanded the boundaries of what is achievable with deep learning, opening new avenues and opportunities in various fields including healthcare, finance, transportation, and entertainment.
|
||
|
||
Companies and organizations worldwide are recognizing the transformative potential of deep learning, investing heavily in research and development to harness its power in offering innovative solutions, optimizing operations, and creating new business opportunities. As deep learning continues its upward trajectory, it is poised to revolutionize how we interact with technology, making our lives more convenient, safe, and connected.
|
||
|
||
### Applications of Deep Learning
|
||
|
||
Deep learning is widely used in many industries today. It is used in finance for things such as stock market prediction, risk assessment, and fraud detection. It is also used in marketing for things such as customer segmentation, personalization, and content optimization. In healthcare, machine learning is used for tasks such as diagnosis, treatment planning, and patient monitoring. It has had a transformational impact on our society.
|
||
|
||
An example of the transformative impact that machine learning has had on society is how it has saved money and lives. For example, as mentioned earlier, deep learning algorithms can make predictions about stocks, like predicting whether they will go up or down. These predictions guide investment strategies and improve financial decisions. Similarly, deep learning can also make medical predictions to improve patient diagnosis and save lives. The possibilities are endless and the benefits are clear. Machine learning is not only able to make predictions with greater accuracy than humans but it is also able to do so at a much faster pace.
|
||
|
||
Deep learning has been applied to manufacturing to great effect. By using software to constantly learn from the vast amounts of data collected throughout the manufacturing process, companies are able to increase productivity while reducing wastage through improved efficiency. Companies are benefiting financially from these effects while customers are receiving better quality products at lower prices. Machine learning enables manufacturers to constantly improve their processes to create higher quality goods faster and more efficiently than ever before.
|
||
|
||
Deep learning has also improved products that we use daily like Netflix recommendations or Google Translate's text translations, but it also allows companies such as Amazon and Uber to save money on customer service costs by quickly identifying unhappy customers.
|
||
|
||
### Relevance to Embedded AI
|
||
|
||
Embedded AI, which involves integrating AI algorithms directly into hardware devices, naturally benefits from the capabilities of deep learning. The synergy of deep learning algorithms with embedded systems has paved the way for intelligent, autonomous devices capable of sophisticated on-device data processing and analysis. Deep learning facilitates the extraction of intricate patterns and information from input data, making it a vital tool in the development of smart embedded systems, ranging from household appliances to industrial machines. This union aims to foster a new era of smart, interconnected devices that can learn and adapt to user behaviors and environmental conditions, optimizing performance and offering unprecedented levels of convenience and efficiency.
|
||
|
||
## Neural Networks
|
||
|
||
|
||
Deep learning takes inspiration from the human brain's neural networks to create patterns utilized in decision-making. This section explores the foundational concepts that comprise deep learning, offering insights into the underpinnings of more complex topics explored later in this primer.
|
||
|
||
Neural networks form the basis of deep learning, drawing inspiration from the biological neural networks of the human brain to process and analyze data in a hierarchical manner. Below, we dissect the primary components and structures commonly found in neural networks.
|
||
|
||
### Perceptrons
|
||
|
||
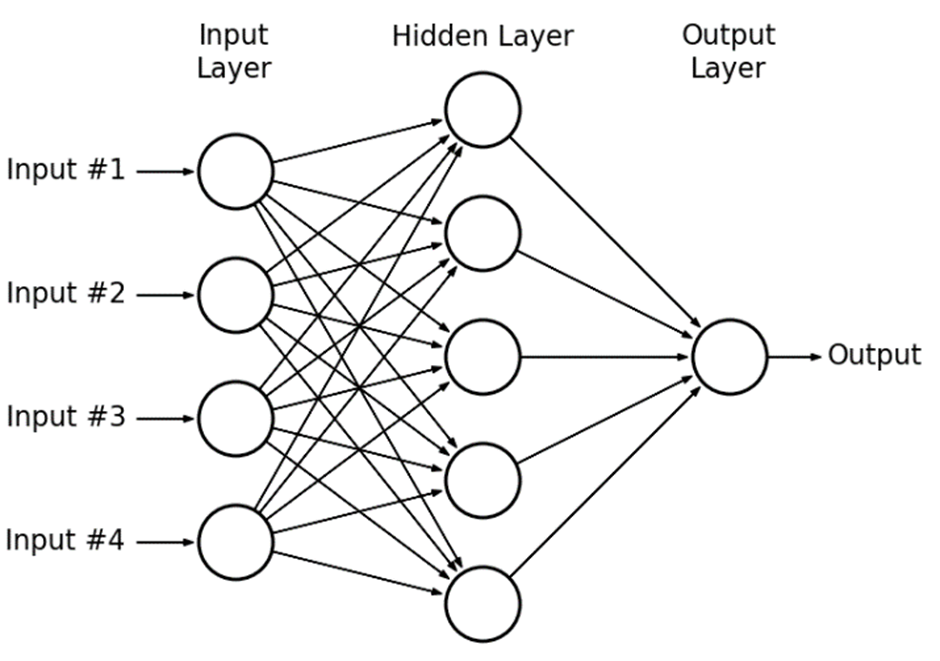
At the foundation of neural networks is the perceptron, a basic unit or node that forms the basis of more complex structures. A perceptron receives various inputs, applies weights and a bias to these inputs, and then employs an activation function to produce an output as shown below in @fig-perceptron.
|
||
|
||
{#fig-perceptron}
|
||
|
||
Initially conceptualized in the 1950s, perceptrons paved the way for the development of more intricate neural networks, serving as a fundamental building block in the field of deep learning.
|
||
|
||
|
||
### Multi-layer Perceptrons
|
||
|
||
Multi-layer perceptrons (MLPs) evolve from the single-layer perceptron model, incorporating multiple layers of nodes connected in a feedforward manner. These layers include an input layer to receive data, several hidden layers to process this data, and an output layer to generate the final results. MLPs excel in identifying non-linear relationships, utilizing a backpropagation technique for training, wherein the weights are optimized through a gradient descent algorithm.
|
||
|
||
|
||
|
||
### Activation Functions
|
||
|
||
Activation functions stand as vital components in neural networks, providing the mathematical equations that determine a network's output. These functions introduce non-linearity to the network, facilitating the learning of complex patterns by allowing the network to adjust weights based on the error during the learning process. Popular activation functions encompass the sigmoid, tanh, and ReLU (Rectified Linear Unit) functions.
|
||
|
||

|
||
|
||
|
||
### Computational Graphs
|
||
|
||
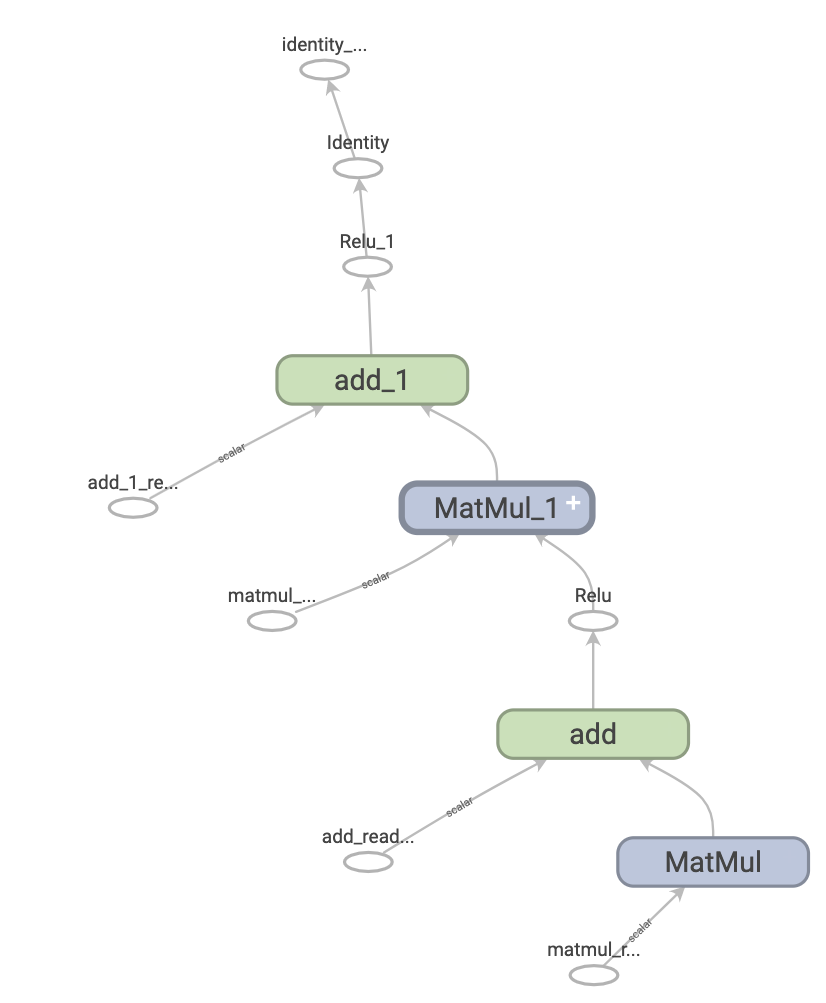
Deep learning employs computational graphs to illustrate the various operations and their interactions within a neural network. This subsection explores the essential phases of computational graph processing.
|
||
|
||
|
||
|
||
#### Forward Pass
|
||
|
||
The forward pass denotes the initial phase where data progresses through the network from the input to the output layer. During this phase, each layer conducts specific computations on the input data, utilizing weights and biases before passing the resulting values onto subsequent layers. The ultimate output of this phase is employed to compute the loss, representing the disparity between the predicted output and actual target values.
|
||
|
||
#### Backward Pass (Backpropagation)
|
||
|
||
Backpropagation signifies a pivotal algorithm in the training of deep neural networks. This phase involves computing the gradient of the loss function with respect to each weight using the chain rule, effectively maneuvering backwards through the network. The gradients calculated in this step guide the adjustment of weights with the objective of minimizing the loss function, thereby enhancing the network's performance with each iteration of training.
|
||
|
||
Grasping these foundational concepts paves the way to understanding more intricate deep learning architectures and techniques, fostering the development of more sophisticated and efficacious applications, especially within the realm of embedded AI systems.
|
||
|
||
{{< video https://www.youtube.com/embed/aircAruvnKk?si=qfkBf8MJjC2WSyw3 >}}
|
||
|
||
### Training Concepts
|
||
|
||
In the realm of deep learning, it's crucial to comprehend various key concepts and terms that set the foundation for creating, training, and optimizing deep neural networks. This section clarifies these essential concepts, providing a straightforward path to delve deeper into the intricate dynamics of deep learning. Overall, ML training is an iterative process. An untrained neural network model takes some features as input and makes a forward prediction pass. Given some ground truth about the prediction, which is known during the training process, we can compute a loss using a loss function and update the neural network parameters during the backward pass. We repeat this process until the network converges towards correct predictions with satisfactory accuracy.
|
||
|
||

|
||
|
||
#### Loss Functions
|
||
|
||
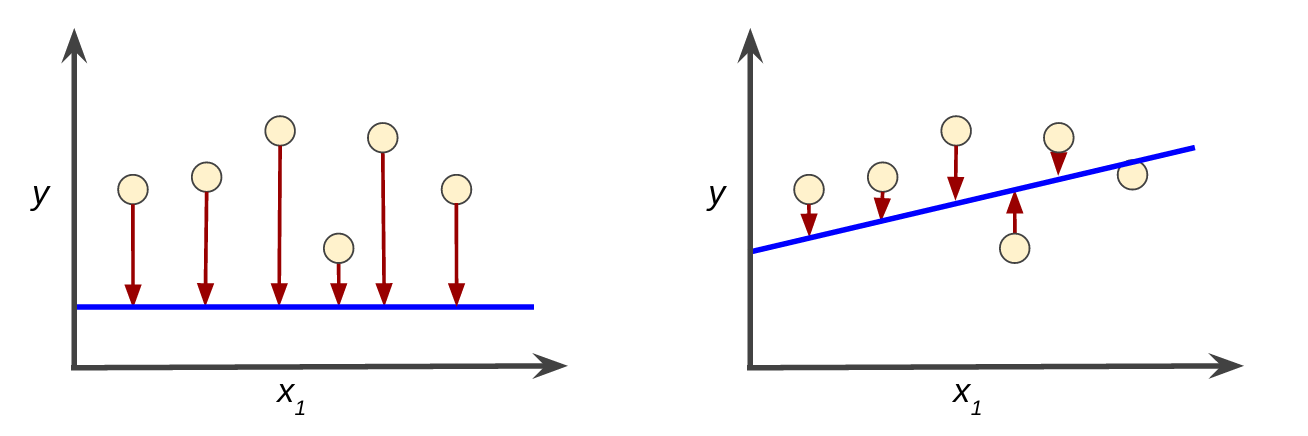
Loss functions, also known as cost functions, quantify how well a neural network is performing by calculating the difference between the actual and predicted outputs. The objective during the training process is to minimize this loss function to improve the model's accuracy. As @fig-loss shows, models can either have high loss or low loss depending on where in the training phase the network is in.
|
||
|
||
{#fig-loss}
|
||
|
||
Various loss functions are employed depending on the specific task, such as [mean squared error](https://developers.google.com/machine-learning/crash-course/descending-into-ml/training-and-loss), log loss and cross-entropy loss for regression tasks and categorical crossentropy for classification tasks.
|
||
|
||
#### Optimization Algorithms
|
||
|
||
Optimization algorithms play a crucial role in the training process, aiming to minimize the loss function by adjusting the model's weights. These algorithms navigate through the model's parameter space to find the optimal set of parameters that yield the minimum loss. Some commonly used optimization algorithms are:
|
||
|
||
- **Gradient Descent:** A first-order optimization algorithm that uses the gradient of the loss function to move the weights in the direction that minimizes the loss.
|
||
- **Stochastic Gradient Descent (SGD):** A variant of gradient descent that updates the weights using a subset of the data, thus accelerating the training process.
|
||
- **Adam:** A popular optimization algorithm that combines the benefits of other extensions of gradient descent, often providing faster convergence.
|
||
|
||

|
||
|
||
#### Regularization Techniques
|
||
|
||
To prevent [overfitting](https://www.mathworks.com/discovery/overfitting.html) and help the model generalize better to unseen data, regularization techniques are employed. These techniques penalize the complexity of the model, encouraging simpler models that can perform better on new data.
|
||
|
||

|
||
|
||
Common regularization techniques include:
|
||
|
||
- **L1 and L2 Regularization:** These techniques add a penalty term to the loss function, discouraging large weights and promoting simpler models.
|
||
- **Dropout:** A technique where randomly selected neurons are ignored during training, forcing the network to learn more robust features.
|
||
- **Batch Normalization:** This technique normalizes the activations of the neurons in a given layer, improving the stability and performance of the network.
|
||
|
||
Understanding these fundamental concepts and terms forms the backbone of deep learning, setting the stage for a more in-depth exploration into the intricacies of various deep learning architectures and their applications, particularly in embedded AI systems.
|
||
|
||
### Model Architectures
|
||
|
||
Deep learning architectures refer to the various structured approaches that dictate how neurons and layers are organized and interact in neural networks. These architectures have evolved to address different problems and data types efficiently. This section provides an overview of some prominent deep learning architectures and their characteristics.
|
||
|
||
#### Multi-Layer Perceptrons (MLPs)
|
||
|
||
MLPs are fundamental deep learning architectures, consisting of three or more layers: an input layer, one or more hidden layers, and an output layer. These layers are fully connected, meaning every neuron in a layer is connected to every neuron in the preceding and succeeding layers. MLPs can model complex functions and find applications in a wide range of tasks, including regression, classification, and pattern recognition. Their ability to learn non-linear relationships through backpropagation makes them a versatile tool in the deep learning arsenal.
|
||
|
||
In embedded AI systems, MLPs can serve as compact models for simpler tasks, such as sensor data analysis or basic pattern recognition, where computational resources are constrained. Their capability to learn non-linear relationships with relatively less complexity makes them a viable option for embedded systems.
|
||
|
||
#### Convolutional Neural Networks (CNNs)
|
||
|
||
CNNs are primarily used in image and video recognition tasks. This architecture uses convolutional layers that apply a series of filters to the input data to identify various features such as edges, corners, and textures. A typical CNN also includes pooling layers that reduce the spatial dimensions of the data, and fully connected layers for classification. CNNs have proven highly effective in tasks like image recognition, object detection, and computer vision applications.
|
||
|
||
In the realm of embedded AI, CNNs are pivotal for image and video recognition applications, where real-time processing is often required. They can be optimized for embedded systems by employing techniques such as quantization and pruning to reduce memory usage and computational demands, enabling efficient object detection and facial recognition functionalities in devices with limited computational resources.
|
||
|
||
#### Recurrent Neural Networks (RNNs)
|
||
|
||
RNNs are suited for sequential data analysis, such as time series forecasting and natural language processing. In this architecture, connections between nodes form a directed graph along a temporal sequence, allowing information to be carried across sequences through hidden state vectors. Variations of RNNs include Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU), which are designed to capture longer dependencies in sequence data.
|
||
|
||
In embedded systems, these networks can be implemented in voice recognition systems, predictive maintenance, or in IoT devices where sequential data patterns are prevalent. Optimizations specific to embedded platforms can help in managing their typically high computational and memory requirements.
|
||
|
||
#### Generative Adversarial Networks (GANs)
|
||
|
||
GANs consist of two networks, a generator and a discriminator, that are trained simultaneously through adversarial training [@goodfellow2020generative]. The generator produces data that tries to mimic the real data distribution, while the discriminator aims to distinguish between real and generated data. GANs are widely used in image generation, style transfer, and data augmentation.
|
||
|
||
In embedded contexts, GANs could be used for on-device data augmentation to enhance the training of models directly on the embedded device, facilitating continual learning and adaptation to new data without the need for cloud computing resources.
|
||
|
||
#### Autoencoders
|
||
|
||
Autoencoders are neural networks used for data compression and noise reduction [@bank2023autoencoders]. They are structured to encode input data into a lower-dimensional representation and then decode it back to the original form. Variations like Variational Autoencoders (VAEs) introduce probabilistic layers that allow for generative properties, finding applications in image generation and anomaly detection.
|
||
|
||
Implementing autoencoders can assist in efficient data transmission and storage, enhancing the overall performance of embedded systems with limited computational and memory resources.
|
||
|
||
#### Transformer Networks
|
||
|
||
Transformer networks have emerged as a powerful architecture, especially in the field of natural language processing [@vaswani2017attention]. These networks use self-attention mechanisms to weigh the influence of different input words on each output word, facilitating parallel computation and capturing complex patterns in data. Transformer networks have led to state-of-the-art results in tasks such as language translation, summarization, and text generation.
|
||
|
||
These networks can be optimized to perform language-related tasks directly on-device. For instance, transformers can be utilized in embedded systems for real-time translation services or voice-assisted interfaces, where latency and computational efficiency are critical factors. Techniques such as model distillation which we will discss later on can be employed to deploy these networks on embedded devices with constrained resources.
|
||
|
||
Each of these architectures serves specific purposes and excel in different domains, offering a rich toolkit for tackling diverse problems in the realm of embedded AI systems. Understanding the nuances of these architectures is vital in designing effective and efficient deep learning models for various applications.
|
||
|
||
## Libraries and Frameworks
|
||
|
||
In the world of deep learning, the availability of robust libraries and frameworks has been a cornerstone in facilitating the development, training, and deployment of models, particularly in embedded AI systems where efficiency and optimization are key. These libraries and frameworks are often equipped with pre-defined functions and tools that allow for rapid prototyping and deployment. This section sheds light on popular libraries and frameworks, emphasizing their utility in embedded AI scenarios.
|
||
|
||
### TensorFlow
|
||
|
||
[TensorFlow](https://www.tensorflow.org/), developed by Google [@abadi2016tensorflow], stands as one of the premier frameworks for developing deep learning models. Its ability to work seamlessly with embedded systems comes from [TensorFlow Lite](https://www.tensorflow.org/lite), a lightweight solution designed to run on mobile and embedded devices. TensorFlow Lite enables the execution of optimized models on a variety of platforms, making it easier to integrate AI functionalities in embedded systems. For TinyML we will be dealing with [TensorFlow Lite for Microcontrollers](https://www.tensorflow.org/lite/microcontrollers).
|
||
|
||
### PyTorch
|
||
|
||
[PyTorch](https://pytorch.org/), an open-source library developed by Facebook [@paszke2019pytorch], is praised for its dynamic computation graph and ease of use. For embedded AI, PyTorch can be a suitable choice for research and prototyping, offering a seamless transition from research to production with the use of the TorchScript scripting language. PyTorch Mobile further facilitates the deployment of models on mobile and embedded devices, offering tools and workflows to optimize performance.
|
||
|
||
### ONNX Runtime
|
||
|
||
The [Open Neural Network Exchange (ONNX)](https://onnx.ai/) Runtime is a cross-platform, high-performance engine for running machine learning models. It is not particularly developed for embedded AI systems, though it supports a wide range of hardware accelerators and is capable of optimizing computations to improve performance in resource-constrained environments.
|
||
|
||
### Keras
|
||
|
||
Keras [@chollet2015] serves as a high-level neural networks API, capable of running on top of TensorFlow, and other frameworks like Theano, or CNTK. For developers venturing into embedded AI, Keras offers a simplified interface for building and training models. Its ease of use and modularity can be especially beneficial in the rapid development and deployment of models in embedded systems, facilitating the integration of AI capabilities with minimal complexity.
|
||
|
||
### TVM
|
||
|
||
TVM is an open-source machine learning compiler stack that aims to enable efficient deployment of deep learning models on a variety of platforms [@chen2018tvm]. Particularly in embedded AI, TVM and µTVM (Micro TVM) can be crucial in optimizing and streamlining models to suit the restricted computational and memory resources, thus making deep learning more accessible and feasible on embedded devices.
|
||
|
||
These libraries and frameworks are pivotal in leveraging the capabilities of deep learning in embedded AI systems, offering a range of tools and functionalities that enable the development of intelligent and optimized solutions. Selecting the appropriate library or framework, however, is a crucial step in the development pipeline, aligning with the specific requirements and constraints of embedded systems.
|
||
|
||
## Embedded AI Challenges
|
||
|
||
Embedded AI systems often operate within environments with constrained resources, posing unique challenges in implementing the deep learning algorithms we discussed above efficiently. In this section, we explore various challenges encountered in the deployment of deep learning in embedded systems and potential solutions to navigate these complexities.
|
||
|
||
### Memory Constraints
|
||
|
||
- **Challenge**: Embedded systems usually have limited memory, which can be a bottleneck when deploying large deep learning models.
|
||
- **Solution**: Employing model compression techniques such as pruning and quantization to reduce the memory footprint without significantly affecting performance.
|
||
|
||
### Computational Limitations
|
||
|
||
- **Challenge**: The computational capacity in embedded systems can be limited, hindering the deployment of complex deep learning models.
|
||
- **Solution**: Utilizing hardware acceleration through GPUs or dedicated AI chips to boost computational power, and optimizing models for inference through techniques like layer fusion.
|
||
|
||
### Energy Efficiency
|
||
|
||
- **Challenge**: Embedded systems, particularly battery-powered devices, require energy-efficient operations to prolong battery life.
|
||
- **Solution**: Implementing energy-efficient neural networks that are designed to minimize energy consumption during operation, and employing dynamic voltage and frequency scaling to adjust the power consumption dynamically.
|
||
|
||
### Data Privacy and Security
|
||
|
||
- **Challenge**: Embedded AI systems often process sensitive data, raising concerns regarding data privacy and security.
|
||
- **Solution**: Employing on-device processing to keep sensitive data on the device itself, and incorporating encryption and secure channels for any necessary data transmission.
|
||
|
||
### Real-Time Processing Requirements
|
||
|
||
- **Challenge**: Many embedded AI applications demand real-time processing to provide instantaneous responses, which can be challenging to achieve with deep learning models.
|
||
- **Solution**: Streamlining the model through methods such as model distillation to reduce complexity and employing real-time operating systems to ensure timely processing.
|
||
|
||
### Model Robustness and Generalization
|
||
|
||
- **Challenge**: Ensuring that deep learning models are robust and capable of generalizing well to unseen data in embedded AI settings.
|
||
- **Solution**: Incorporating techniques like data augmentation and adversarial training to enhance model robustness and improve generalization capabilities.
|
||
|
||
### Integration with Existing Systems
|
||
|
||
- **Challenge**: Integrating deep learning capabilities into existing embedded systems can pose compatibility and interoperability issues.
|
||
- **Solution**: Adopting modular design approaches and leveraging APIs and middleware solutions to facilitate smooth integration with existing systems and infrastructures.
|
||
|
||
### Scalability
|
||
|
||
- **Challenge**: Scaling deep learning solutions to cater to a growing number of devices and users in embedded AI ecosystems.
|
||
- **Solution**: Utilizing cloud-edge computing paradigms to distribute computational loads effectively and ensuring that the models can be updated seamlessly to adapt to changing requirements.
|
||
|
||
Understanding and addressing these challenges are vital in the successful deployment of deep learning solutions in embedded AI systems. By adopting appropriate strategies and solutions, developers can navigate these hurdles effectively, fostering the creation of reliable, efficient, and intelligent embedded AI systems.
|
||
|
||
## Limitations of Deep Learning
|
||
|
||
Choosing the right approach between traditional machine learning and deep learning hinges on various factors that delineate the complexity and nature of the problem at hand. This section aims to provide a balanced perspective that assists practitioners, researchers, and enthusiasts in making well-informed decisions while selecting between traditional machine learning and deep learning approaches for their specific tasks and projects.
|
||
|
||
### The Predicament
|
||
|
||
Deep learning, although powerful, is not a universal solution for every problem. Its effectiveness often comes at the cost of requiring substantial data and computational resources. Moreover, deep learning models, especially deep neural networks, are often perceived as "black boxes", offering no clear insight into their decision-making process, which can be a significant downside in sectors where interpretability is critical.
|
||
|
||
Traditional machine learning, encompassing various algorithms and methodologies like decision trees, support vector machines, and logistic regression, retains significant value in data analytics and predictive modeling. It often presents several advantages including better interpretability, efficiency, and suitability for smaller datasets.
|
||
|
||
### Traditional ML vs Deep Learning
|
||
|
||
To succinctly highlight the differences, a comparative table illustrates the contrasting characteristics between traditional ML and deep learning:
|
||
|
||
| Aspect | Traditional ML | Deep Learning |
|
||
|----------------------------|-----------------------------------------------------|--------------------------------------------------------|
|
||
| Data Requirements | Low to Moderate (efficient with smaller datasets) | High (requires large datasets for nuanced learning) |
|
||
| Model Complexity | Moderate (suitable for well-defined problems) | High (detects intricate patterns, suited for complex tasks) |
|
||
| Computational Resources | Low to Moderate (cost-effective, less resource-intensive) | High (demands substantial computational power and resources) |
|
||
| Deployment Speed | Fast (quicker training and deployment cycles) | Slow (prolonged training times, especially with larger datasets) |
|
||
| Interpretability | High (clear insights into decision pathways) | Low (complex layered structures, "black box" nature) |
|
||
| Maintenance | Easier (simple to update and maintain) | Complex (requires more efforts in maintenance and updates) |
|
||
|
||
### Choosing Traditional ML vs. DL
|
||
|
||
#### Data Availability and Volume
|
||
|
||
- **Quantity of Data**: Traditional machine learning models, like decision trees or Naive Bayes, are often favorable when data availability is limited, providing robust predictions even with smaller datasets. This is evident in scenarios such as disease prediction in medical diagnostics and customer segmentation in marketing.
|
||
|
||
- **Data Diversity and Quality**: Traditional machine learning models are versatile in handling various data types, often requiring less preprocessing compared to deep learning models. They may also offer more robust predictions in scenarios with noisy data.
|
||
|
||
#### Complexity of the Problem
|
||
|
||
- **Problem Granularity**: Simple to moderately complex problems, which can have linear or polynomial relationships between variables, often find a better match with traditional machine learning techniques.
|
||
|
||
- **Hierarchical Feature Representation**: Deep learning models excel in tasks requiring hierarchical feature representation like image and speech recognition. However, not all problems demand this level of complexity, and traditional machine learning algorithms might sometimes provide more straightforward and equally accurate solutions.
|
||
|
||
#### Hardware and Computational Resources
|
||
|
||
- **Resource Constraints**: The availability of computational resources often dictates the choice between traditional ML and deep learning, with the former being less resource-intensive and thereby preferable in environments with hardware limitations or budget constraints.
|
||
|
||
- **Scalability and Speed**: Traditional machine learning models, like support vector machines (SVM), often allow for quicker training times and graceful scalability, especially advantageous in projects with tight timelines and increasing data volumes.
|
||
|
||
#### Regulatory Compliance
|
||
|
||
Regulatory compliance is paramount in several industries, necessitating adherence to guidelines and best practices such as GDPR in the EU. Traditional ML models, due to their inherent interpretability, often align better with these regulations, especially in sectors like finance and healthcare.
|
||
|
||
#### Interpretability
|
||
|
||
Understanding the decision-making process is simpler with traditional machine learning techniques, as opposed to deep learning models that function as a "black box", making the tracing of decision pathways challenging.
|
||
|
||
### Making an Informed Choice
|
||
|
||
Given the constraints of embedded AI systems, understanding the nuances between traditional ML techniques and deep learning becomes critical. Both avenues offer unique advantages, and their distinct characteristics often dictate the choice of one over the other in different scenarios.
|
||
|
||
With all that said, deep learning has been steadily outpacing traditional machine learning methods in several critical areas due to a combination of data abundance, computational advancements, and proven efficacy in complex tasks.
|
||
|
||
Here are a few concrete reasons why we are centering our attention on deep learning in this text:
|
||
|
||
1. **Superior Performance in Complex Tasks**: Deep learning models, especially deep neural networks, excel in tasks where the relationships between data points are incredibly complex. Tasks such as image and speech recognition, language translation, and playing intricate games like Go and Chess have seen breakthroughs primarily through deep learning algorithms.
|
||
|
||
2. **Efficient Handling of Unstructured Data**: Unlike traditional machine learning methods, deep learning can process unstructured data more effectively. This is a vital asset in the modern data landscape where a vast majority of data is unstructured, including text, images, and videos.
|
||
|
||
3. **Leveraging Big Data**: With the availability of big data, deep learning models have the ability to continually learn and improve. These models are adept at utilizing large datasets to enhance their predictive accuracy, something that can be limiting in traditional machine learning approaches.
|
||
|
||
4. **Hardware Advancements and Parallel Computing**: The development of powerful GPUs and the availability of cloud computing platforms have enabled the rapid training of deep learning models. These advancements have addressed one of the significant hurdles of deep learning – the requirement of substantial computational resources.
|
||
|
||
5. **Dynamic Adaptability and Continuous Learning**: Deep learning models are capable of adapting to new information or data dynamically. They can be trained to generalize their learning to new, unseen data, which is essential in rapidly evolving fields such as autonomous driving or real-time language translation.
|
||
|
||
Despite the traction gained by deep learning, it's imperative to understand that traditional machine learning is not obsolete. While we delve deeper into the nuances of deep learning, we will also highlight situations where traditional machine learning methods may be more appropriate due to their simplicity, efficiency, and ease of interpretation. By focusing on deep learning in this text, we aim to equip readers with the knowledge and tools necessary to tackle modern, complex problems in various domains, while also offering insights into the comparative advantages and suitable application scenarios for both deep learning and traditional machine learning methods.
|
||
|
||
## Conclusion
|
||
|
||
Deep learning has emerged as a powerful set of techniques for tackling complex pattern recognition and prediction problems. Beginning with an overview, we delineated the fundamental concepts and principles that govern deep learning, establishing a foundational knowledge that would pave the way for more advanced studies.
|
||
|
||
At the heart of deep learning, we delved into the basic concepts of neural networks, the powerful computational models inspired by the human brain's interconnected neuron structure. This discussion allowed us to appreciate the capabilities and potential of neural networks in crafting sophisticated algorithms that can learn and adapt from data.
|
||
|
||
Understanding the role of libraries and frameworks was a crucial part of our discussion, offering insights into the tools that can help streamline the development and deployment of deep learning models. These resources not only facilitate the implementation of neural networks but also provide avenues for innovation and optimization.
|
||
|
||
Subsequently, we addressed the challenges that one might encounter in embedding deep learning algorithms within embedded systems, offering a critical perspective on the complexities and considerations that come with bringing AI to edge devices.
|
||
|
||
Moreover, we ventured into an examination of the limitations of deep learning. Through a series of discussions, we unraveled the issues faced in deep learning applications and outlined the scenarios where traditional machine learning might supersede deep learning. These sections are instrumental in fostering a balanced view of the capabilities and restrictions of deep learning.
|
||
|
||
In this primer, we equipped you with the knowledge to make informed choices between deploying traditional machine learning or deep learning techniques, depending on the unique demands and constraints of a particular problem.
|
||
|
||
As we conclude this chapter, it is our hope that you are now well-versed with the basic "language" of deep learning, prepared to delve deeper into the subsequent chapters with a solid understanding and critical perspective. The journey ahead is lined with exciting opportunities and challenges that embed AI within systems.
|
||
|